
How To Do a JavaScript Audit for SEO

JavaScript is an essential part of many modern websites, in fact it's the most popular web development languages. But it can also present challenges when it comes to SEO. If not implemented properly, JavaScript can make it difficult for search engines to crawl and index a website which can reflect negatively on the website's performance in SERPs.
I'll walk you through the JS auditing for SEO process step by step, and hopefully by the end of reading this, you'll learn everything you need. I'm also adding a table of content so you can jump to the most relevant sections. So without further ado, let's get started!
TL;DR
But... before you get overwhelmed, here's a template that summarizes everything in this post. If you don't understand something, you can come back to this post for more information!

Get the JavaScript SEO Audit Template
Table of Contents
How does JavaScript impact SEO
JavaScript can impact your website in one of the following ways:
It can slow your website to a great deal (core web vitals/page speed metrics)
It can prevent Google from discovering and crawling URLs on your website.
It can prevent Google from seeing the content on your website (text and images too).
Other search engines, are less efficient in rendering JavaScript than Google.
JS SEO Story!
Second half of 2021, early 2022, there were plenty of complaints among the SEO community about URLs not getting indexed or taking too much time to get indexed. That's when I was also approached by a client to help with indexation issues for their brand new website.
They just launched and didn't have many pages, yet most of the pages were not indexed. The website suffered from the famous "discovered not indexed" syndrome.

To test things, I requested indexation of a page, and it got indexed so we know there's nothing blocking indexation from the technical standpoint, it's just the process is slow.
Started auditing the website, and the moment I switched off JS, the content on the website was no longer visible. Anyways, I wrote an article about this on LinkedIn and got a comment from Martin Split:

But a study by Onely.com contradicts this. In their study, Onely found that:
💡 Google Needs 9X More Time To Crawl JS Than Plain HTML Pages.
Can google crawl JavaScript? Yes but that comes with a cost on website performance. Google's John Muller has a tweet from 2018 where he mentions that JavaScript can slow down website indexation:

In fact just today, I stumbled upon those tweets from Rebekah Edwards asking about a website that saw a significant drop in performance after a redesign. While having a temporary drop in redesigns is not unusual, she noticed that the performance is steadily declining which is alarming. After some discussions, she found that the website is JavaScript heavy.

So in summary, JS can have serious impact on website indexation, and performance. And take everything Google says with a grain of salt.
Additional resource (How can our JavaScript site get indexed better?):
Tools to Audit JavaScript for SEO
I'll start by this list of tools that can help you audit JS issues on your website:
Google search console inspect tool: once you inspect a URL, you can click on "view crawled page" or "live test" and see how google renders the page. You can also use Rich Results Test or Mobile-Friendly Test tools too.

Web Developer Chrome Extension: once you install the extension, go to the web page you want to test, click on the extension icon, click disable JS and then refresh the page and see how does the page look like without JS. If there is missing content then you have JS issues on your website.
View Rendered Source Chrome Extension: this tool shows you the raw html, the rendered code (after JS is executed) and the difference between the 2.

Last but not least, Screaming frog: if you are dealing with a huge website with a big number of URLs you may want to consider the cloud version vs the desktop version of the crawler. Anyways, using screaming frog, you can compare the raw and rendered HTML code and spot the differences. You'll need the paid version of this tool. Go to configuration --> spider --> crawl tab and make sure the JavaScript item is checked:

Then go to the rendering tab, and select JS and make sure items are checked as follows:

Then crawl the website. You can also use Screaming Frog to find blocked resources (more details below).
How to Audit JavaScript for SEO
When I'm doing a technical audit, or a post-migration/redesign audit, here's what I do to check if JavaScript is not negatively impacting SEO.
Disable JavaScript
This is perhaps the most straight forward way to see what's going on, on a website. There are different ways you can do this,. The way I prefer is using the Web Developer Chrome Extension. Simply install the extension, click on the extension icon in chrome bar, click on disable JavaScript and refresh the page!

Once you do that, look at the page. Sometimes the situation will be obvious, you will not see anything on the page, and sometimes you need to check for different elements like:
Are internal links and top and footer navigation links working?
Is the content on the page visible? Check for body content, content in accordions. A good way to implement accordions is to allow the whole text to be visible on the page if JS is switched off. Here's an example from this URL.
Accordion with JS enabled. You need to click to see the text:

Accordion with JS disabled. Text becomes automatically visible on the page, which mean that Google can see the text without having to process JS (perfect!):

It is worth noting that Gary Illyes, recommended restructure the JS calls such that the content loads first and see if that helps with any issues. Here's his post on LinkedIn:

How to explain the issue to your developer?
We want to make sure that all the content on the page is directly available in the raw HTML code. If links in navigation or internal links are not visible with JS disabled, this mean Google will not be able to see them and crawl those linked URLs. Same with content.
We also want to make sure that all internal links are created using the ahref attribute as per Google's recommendations. Example:
💡 <a href=”link”>anchor text</a>
Watch Out When Lazy Loading Images
Lazy loading is a very popular technique where content identified as non-important is not loaded until its needed. This is commonly used with images for example to reduce the real and perceived loading time.
💡 Important Unrelated Note: Lazy load only images that are below the fold, as lazy loading images above the fold can actually have a negative impact on Core Web Vital metrics.
Some popular Lazy Loading JS based libraries use a "data-src" attribute instead of the "src" attribute for image source in HTML. Without going into much details about this, simply open page source code and look for "data-scr" attribute. If you find any, this means that your images may not be indexed by Google.
Image attributes should look something like this:
💡 <img src="example.com/paris.jpg" alt="Paris" style="width:100%">
They can also use lazy loading like this:
💡 <img src="example.com/paris.jpg" alt="Paris" style="width:100%" loading="lazy">
How to explain the issue to your developer?
We want to make sure that all images on the website are indexed as they can bring valuable traffic from image search. Without having the "src" attribute, google may not be able to access and index those images. So we recommend using Native Lazy Loading instead.
Don't Count Buttons as Internal Links
Rule of thumb, google cannot click on buttons. Google does not interact with the page the same way users do. So, when analyzing the internal linking of the website, do not count buttons as internal links. There's not much to test for here, just something to keep in mind.
Infinite Scroll (Lazy Loading New Content)
Infinite scroll is a feature used to dynamically load more content once users scroll to the end of the page. It is commonly used in blog category pages and ecommerce category pages.
If your website is using infinite scroll, know that Google does not scroll through pages, as Google does not behave the same way as users on a page. This means that using infinite scroll can cause indexation issues as some URLs will not be discovered and therefore crawled by Google.
To test what google can see on a page, you can use the "Rich Result Test Tool":

Click on "screenshot" and you'll be able to see what can Google see on a page and what not. To overcome the limitations of infinite scroll, one option would be using paginated loading.
How to implement paginated loading?
Basically we want to make sure that as users scroll through the content, and new content starts to load, the page URL is also updated to be (for example ?page=2). The easiest way to understand this is by checking the demo for infinite scroll created by John Muller.
💡 I wouldn't stress out about infinite scroll unless you notice indexation issues. Remember that Google can still pickup URLs from the sitemap and not necessarily thought internal linking. I'd be more concerned if this was impacting performance in SERPs as there would be plenty of orphaned pages. More concerned if any of those pages are important for the business (i.e. a top product page). Infinite scroll is more of an issue for bigger websites vs small websites.
How to explain the issue to your developer?
We want to make sure that Google can access and index all pages on our website. We recommend using paginated loading. All the information your developer would need about paginated loading can be found here.
💡 Rememeber: Google doesn't interact with you content, doesn't click on buttons and doesn't scroll.
Fragment URLs
Using URLs with # is fine if you're using them as jump links for example. Here's Google official statement about fragment URLs:
💡 Fragments are supposed to be used to address a piece of content within the page and when used for this purpose, fragments are absolutely fine. [Source]
And you will also notice these URLs can appear in GSC performance report and that's ok too. So basically fragmented URLs, like the ones in the table of content on this blog post are ok, since they take to parts of the content that is already on the page.
But using fragment URLs to show content that is not on the page will not work with Googlebot. Js Frameworks like Angular and Vue generate URLs with a hash (#) and Google ignores those URLs. Here's how Google explains it:
💡 Sometimes developers decide to use fragments with JavaScript to load different content than what is on the page without the fragment. That is not what fragments are meant for and won't work with Googlebot. [Source]
How to explain the issue to your developer?
We want to make sure that each page has a unique URL. Using JavaScript and fragmented URLs to change the content of the existing page is not a good practice and will cause issues with website performance in SERPs.
Robots.txt
Make sure that your robots.txt file does not block JavaScript files. If Google cannot access your JavaScript files, it will not be able to render the content of your website correctly.
Example:

For my website, I checked the robots.txt file here, and simply checked that all folders marked as Disallow are not JS files or folders that contain JS files.
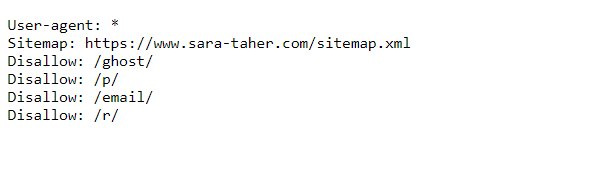
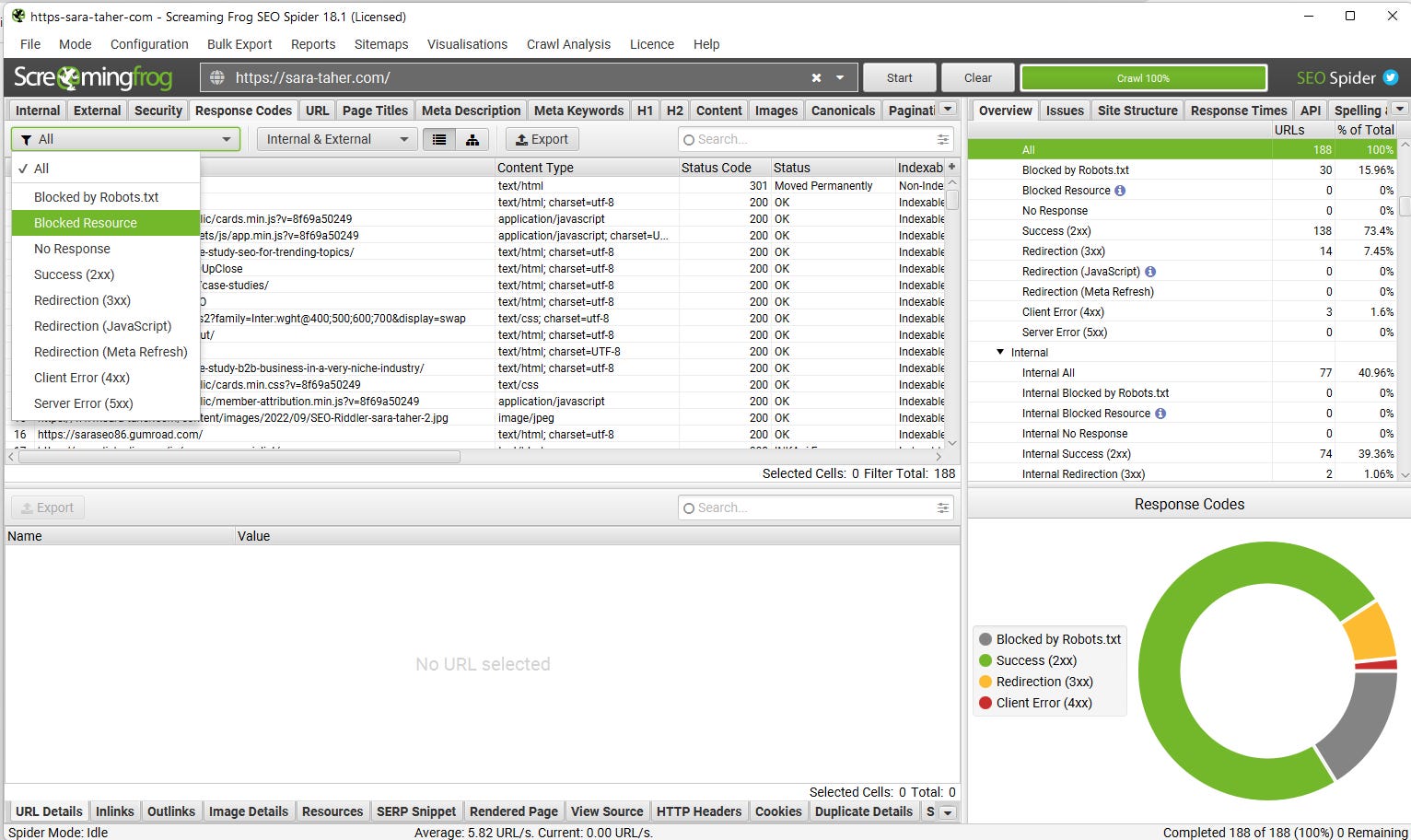
You can also use Screaming Frog and find blocked resources:
How to explain the issue to your developer?
We want to make sure that Google can render the website correctly. To do so, we need to make sure that no critical JS files are blocked from being crawled in robots.txt.
Google Search Console Crawl Stats Report
A good place to check and see how much JavaScript files are crawled on your website is to check the Crawl stats report in GSC. It's found under settings:

Once you click on this report you can see data on crawl stats (obviously from the name :) ) You can see how much JS is being crawled on your website, as well as images and other file types. It's good to check this report regularly. You can find

To learn more about this report, check this video:
Server-Side Rendering
You've probably heard about server-side, and client-side rendering.
Client-side rendering: If you use a JavaScript framework, the default is client-side rendering. This means that the JavaScript files are executed in your browser and not on the server.
Server-side rendering: this means the rendering of JavaScript is already done on the server and your browser is just showing the end result.
Why is client-side rendering a concern for SEO?
Client-side rendering means that JavaScript adds seconds of load time to a page which is not ideal for user experience. More importantly, using client side-rendering is reported to cause poor performance in SERPs as JavaScript issues can block your page or some of the content on the page from showing up in Google Search.
When is client-side rendering not a problem?
Some websites render specific parts of the page client-side. For example if your website has an embedded review widget that pulls its data from another website, this may be implemented using client-side rendering.
I'd say for these type of situations, I'd evaluate the situation on a case by case basis. Sometimes this part of content is not essential for ranking or is not considered a core part of the content of the page and so you may want to ignore the situation all together because the impact vs effort to change to total server-side rendering may not be worth it.
How do I know if server-side or client-side?
The easiest way to check that is to check the source code (html) of the page. Right click, select "view page source". If the source code is contains very little code, this means that the website is using client side rendering.
Dynamic Rendering
In a perfect world, we'd like all our websites to have server-side rendering so the page content is delivered to Google ready for indexing. But that's not the case, and we're not in a perfect world.
An alternative was "dynamic rendering", where the server serves different content based on user-agent. If a user requests a page, the sever serves the usual JavaScript version of the page, but if Google requests the page, the server serves an HTML version of the page.
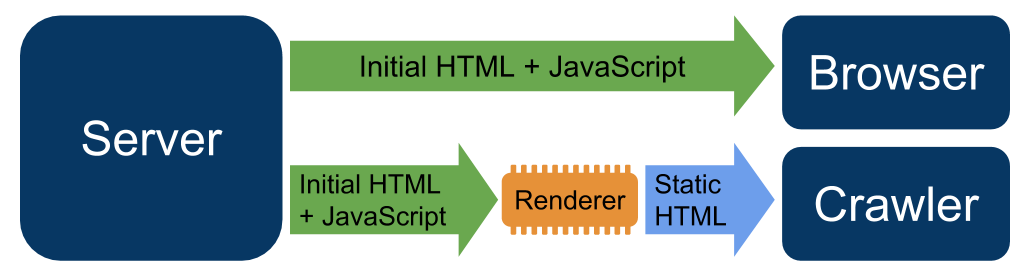
Google announced recently that this is no longer a valid long term solution for websites using client-side rendering.
💡 Dynamic rendering is a workaround and not a long-term solution for problems with JavaScript-generated content in search engines. Instead, we recommend that you use server-side rendering, static rendering, or hydration as a solution. [Source]
So what's the solution?
Google suggested one of 3 approaches, which I recommend you discuss directly with your developer (that's the easiest way to move forward from this point without getting too technical):
Server-side rendering
Static rendering
Hydration
How to explain the issue to your developer?
Our website is currently using client-side rendering which causes some challenges for Google bot and other search engines. We need to switch to either one of the following options:
JavaScript Redirects
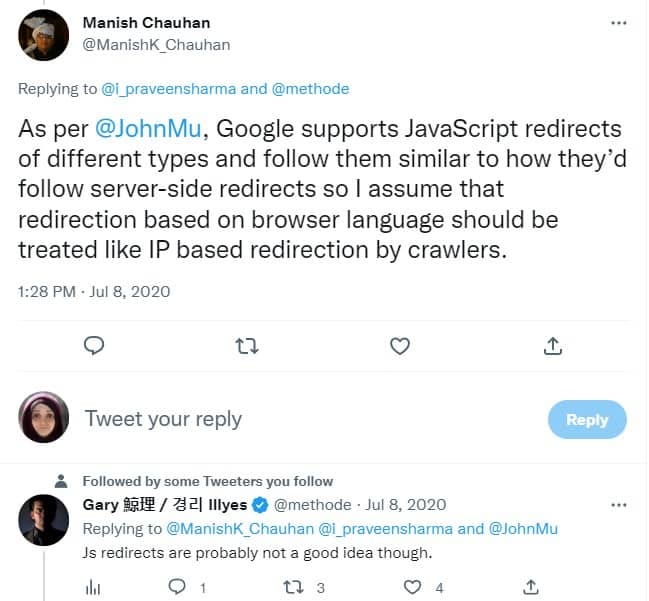
JavaScript can be used to create redirects. Generally speaking, Google does not recommend using JS redirects as other search engines may not pick it up. Here's Google's Gary Illyes talking about this on twitter.
A server side http 301 redirect is the optimal way to create redirects. But there are situations where we cannot implement server site 301 redirects and have to go with JS redirects. JS redirects can create soft 404s if not implemented correctly.
Here's an example code to implement JS redirects:
💡 fetch(`/api/products/${productId}`).then(response => response.json()).then(product => {if(product.exists) {showProductDetails(product); // shows the product information on the page} else {// this product does not exist, so this is an error page.window.location.href = '/not-found'; // redirect to 404 page on the server.}}) [Source]
The easiest way to find JS redirects is by using screaming frog. Crawl the website, go to the response codes tab and select from the drop down menu Redirection (JavaScript)

How to explain the issue to your developer?
JavaScript redirects come with some issues. They are not picked up well by other search engines and may cause soft 404s errors. We recommend using HTTP 301 redirects. If that's not possible, we can create the JavaScript redirect using the example code above.
Is Invisible Content Less Valuable
No, content invisible on the page like content hidden in accordions is not less valuable. This was the case in the past, but this is no longer true. As long as the content is visible in the HTML or the immediate JavaScript and no XHR (JS API to send network requests between the browser and a server) is used to bring in content, hidden content is equally important as the content that is visible on the page and is treated the same and has the same value. [Source]
Can we inject canonical tags using JavaScript?
Yes this is possible. While this is not recommended by Google, you can use JS to inject canonical tags to pages and Google will pickup the canonical tags after rendering the pages. Here's an example on how to do that [Source]:
💡 fetch('/api/cats/' + id).then(function (response) { return response.json(); }).then(function (cat) {// creates a canonical link tag and dynamically builds the URL// e.g. https://example.com/cats/simbaconst linkTag = document.createElement('link');linkTag.setAttribute('rel', 'canonical');linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName;document.head.appendChild(linkTag);});
Conclusion
The topic of JavaScript auditing for SEO is not a small topic that can be handled in one blog post. But I did my best to make sure you have all the important information you need in one place to get you started with JS auditing!